The News: Tesla has integrated the LLVM MLIR (Multi-Level Intermediate Representation) stack into FSD (Supervised) v14.3, rewriting its AI compiler and runtime from the ground up.
Why It Matters: The rewrite delivers a confirmed 20% faster reaction time for HW4 vehicles and accelerates Tesla's ability to iterate on its neural network models — a foundational shift in how FSD thinks.
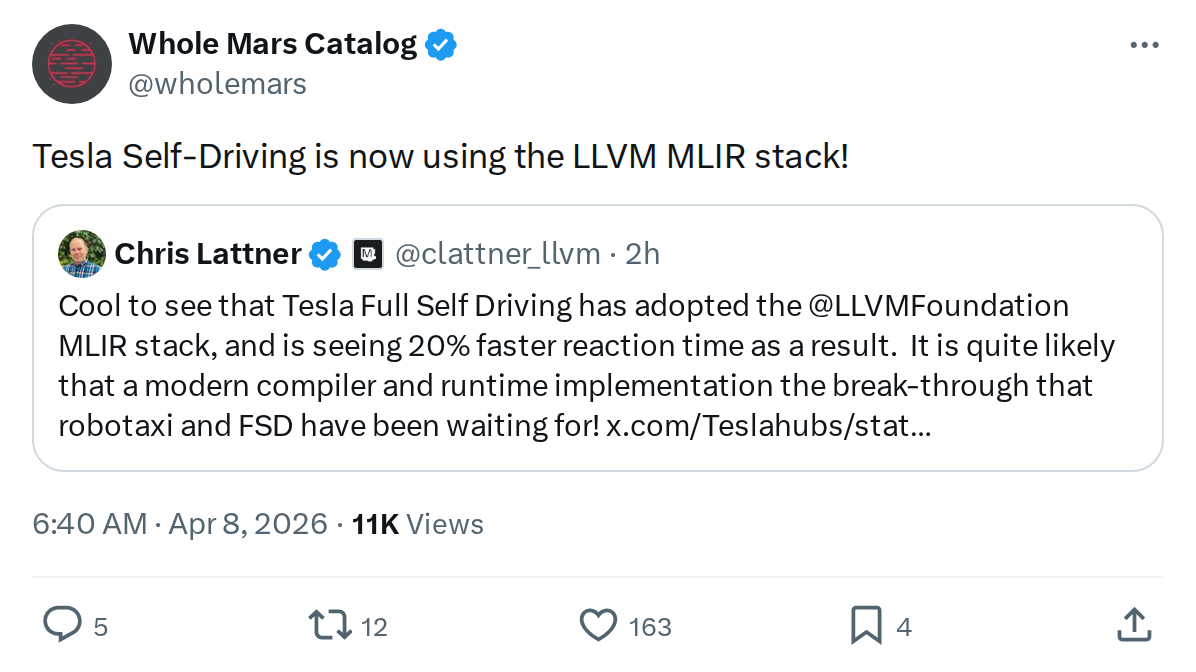
Source: @wholemars on X

Tesla Just Rebuilt FSD's Brain — And It Shows
Tesla's Full Self-Driving software has always been a moving target — constantly updated, constantly improving. But most of those updates are incremental: better lane changes, smoother stops, smarter intersection handling. What landed today with FSD (Supervised) v14.3 (software version 2026.2.9.6) is something categorically different. Tesla didn't just tune the model. They rebuilt the compiler that runs it.
The integration of the LLVM MLIR (Multi-Level Intermediate Representation) stack represents a ground-up rewrite of the AI compiler and runtime that sits beneath FSD's neural networks. In plain terms: the engine that translates Tesla's AI models into instructions for the car's hardware has been completely replaced with a more powerful, more efficient architecture. The headline result is a 20% faster reaction time — and that number comes directly from Tesla's own release notes for v14.3.
📊 Key Figures
| Metric | Value | Context |
|---|---|---|
| Reaction Time Improvement | +20% | Confirmed in official release notes |
| FSD Version | v14.3 | Software 2026.2.9.6 |
| Hardware Requirement | HW4 only | HW3 not supported in this release |
| Rollout Start | April 7, 2026 | Early testers first |
| Compatible Models | S, 3, X, Y, CT | HW4-equipped units only |
Why MLIR Is a Big Deal
MLIR — Multi-Level Intermediate Representation — is a compiler infrastructure framework originally developed at Google and now part of the open-source LLVM project. It was designed specifically to handle the complexity of modern AI workloads: multiple hardware targets, diverse neural network operations, and the need to optimize across many layers of abstraction simultaneously.
Notably, MLIR was created by Chris Lattner, who previously served as VP of Autopilot Software at Tesla. Lattner publicly acknowledged Tesla's adoption of the LLVM Foundation MLIR stack and the reported performance gains — a rare instance of an infrastructure change receiving external validation from someone who knows both the technology and Tesla's internals intimately.
For Tesla specifically, the implications are twofold. First, the immediate performance gain: FSD's neural networks can now execute faster on the car's hardware, which translates directly to the 20% reaction time improvement. In a system where milliseconds matter — merging onto a highway, reacting to a pedestrian stepping off a curb — that is a meaningful real-world delta.
Second, and arguably more important for the long term: model iteration speed. By rebuilding on MLIR, Tesla's engineers can now train, compile, and deploy updated neural networks more efficiently. The compiler is no longer a bottleneck. That means faster improvement cycles, which means FSD gets better, faster. This is the kind of infrastructure investment that pays dividends for years.
What Else Is in v14.3
The MLIR integration doesn't travel alone. FSD v14.3 also includes upgrades to the Reinforcement Learning (RL) stage of FSD's neural network training pipeline, as well as improvements to the neural network vision encoder — the component responsible for understanding what the car's cameras are seeing. According to Tesla's release notes, this enhances 3D geometry comprehension and expands traffic sign recognition.
Practical improvements in this release include better parking spot selection, more confident handling of emergency vehicles and school buses, and improved traffic light processing at complex intersections. These are the kinds of edge cases that have historically tripped up FSD in real-world driving, and they're being addressed in the same release that overhauls the underlying compiler. That combination — infrastructure plus behavioral refinement — suggests a coordinated, deliberate engineering push rather than a routine patch.
🔭 The BASENOR Take
Timeline: Rolling out now to HW4 vehicles. Early testers and prominent Tesla evaluators are among the first recipients as of April 7, 2026.
Impact Level: 🔴 High — This is a foundational architectural change, not a feature update. The 20% reaction time improvement is the most significant single-release performance gain FSD has seen in recent memory.
Confidence: High — Tesla's own release notes confirm the MLIR integration and the 20% figure. Chris Lattner's public acknowledgment adds independent corroboration from a credible technical authority.
The Bottom Line: Tesla has been criticized for iterating slowly on FSD's core architecture while competitors invest heavily in AI infrastructure. The MLIR adoption signals that Tesla is not just updating its models — it's rebuilding the machinery that produces them. If the 20% reaction time improvement holds across diverse real-world conditions, this is the kind of change that moves the needle on FSD's safety and capability profile in a way that no single behavioral fix can match. HW3 owners being excluded from this release is a meaningful data point: the gap between HW3 and HW4 capability is widening, and it's now an architectural gap, not just a sensor one. For owners still on HW3, the pressure to upgrade — or to factor HW4 into their next vehicle decision — just increased.
📰 Deep Dive
The choice to rebuild on LLVM MLIR rather than continuing to extend Tesla's existing compiler infrastructure is a statement about where Tesla believes autonomous driving is headed. MLIR was purpose-built for heterogeneous compute — the kind of environment where you're running neural networks across CPUs, GPUs, and specialized AI accelerators simultaneously. Tesla's HW4 platform, with its custom AI inference chips, is exactly that kind of environment. By aligning its compiler stack with an industry-standard framework that was designed for this use case, Tesla gains not just performance but access to a broader ecosystem of tooling, optimization research, and engineering talent that understands the stack.
The Reinforcement Learning upgrades bundled into v14.3 are worth watching closely. RL has been central to Tesla's approach to training FSD for complex, unscripted scenarios — the situations that rule-based systems and supervised learning alone struggle to handle. Improving the RL training pipeline in the same release that accelerates the compiler suggests Tesla is optimizing the entire model development loop, not just the inference end. Faster training plus faster deployment equals a faster feedback cycle from real-world miles to improved behavior.
For owners following our FSD coverage, the practical question is when v14.3 will reach the broader HW4 fleet. Tesla's typical rollout pattern starts with a small cohort of testers before expanding over days to weeks. Given the depth of the changes in this release — compiler rewrite, RL improvements, vision encoder upgrades — it would be reasonable to expect Tesla to monitor early feedback carefully before accelerating the rollout. If you're on HW4 and subscribed to FSD, check your software update screen over the coming days.

Sarah focuses on Tesla Energy, SpaceX missions, and the broader Musk AI portfolio. Former data analyst in clean energy. Based in San Francisco.
Sources verified at publish time. Spotted an inaccuracy? Email editorial@basenor.com.