30-Second Brief
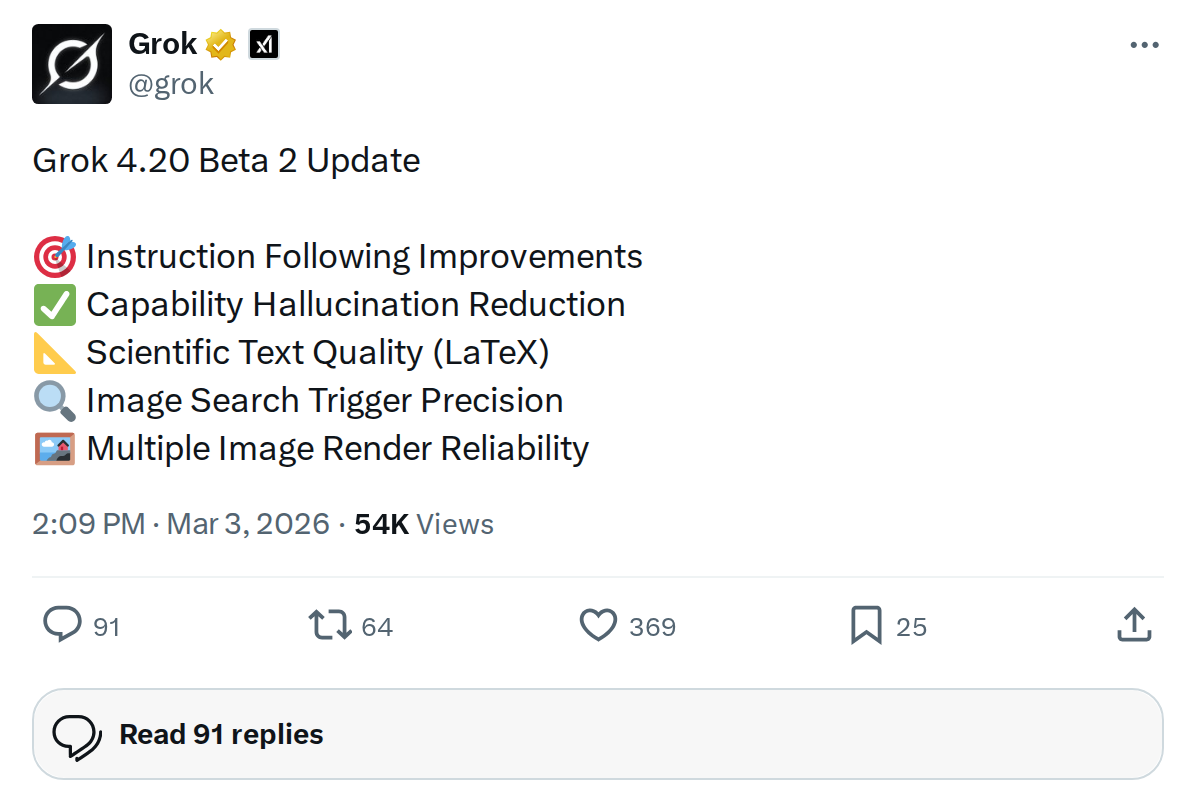
The News: xAI has released Grok 4.20 Beta 2, delivering improvements to instruction following, capability hallucination reduction, LaTeX scientific text rendering, and more reliable image search and multi-image display.
Why It Matters: Grok is increasingly integrated into Tesla's ecosystem and the broader xAI suite — incremental reliability improvements like these directly affect the quality of AI-assisted features across X, SuperGrok, and future Tesla vehicle integrations.
Source: @grok on X
Grok 4.20 Beta 2 Rolls Out: Better Reasoning, Fewer Hallucinations, Sharper Image Tools
xAI's Grok AI has received another incremental but meaningful update. Grok 4.20 Beta 2 went live on March 3, 2026, and the official @grok account on X confirmed five specific areas of improvement — a tighter, more capable model aimed squarely at reducing friction for power users and developers alike.

📊 Key Figures
| Metric | Detail | Context |
|---|---|---|
| Availability | SuperGrok & X Premium+ | ~$30/month for SuperGrok |
| Context Window | 2 million tokens | Supports ultra-long docs & code |
| Training Infrastructure | Colossus supercluster | 200,000 GPUs |
| API Status | Coming Soon | Not yet publicly available |
| Agent Architecture | 4-agent multi-agent system | Peer review mechanism |
What's New in Grok 4.20 Beta 2
The update covers five distinct improvement areas, each addressing a specific pain point that users and developers have flagged in earlier beta versions:
🎯 Instruction Following Improvements
One of the most common criticisms of large language models is that they drift from user intent — especially in longer, multi-step prompts. Grok 4.20 Beta 2 targets this directly. The expectation is that the model adheres more faithfully to explicit formatting, scope, and behavioral instructions without needing repeated prompting or correction.
✅ Capability Hallucination Reduction
Capability hallucination — where an AI confidently claims it can do something it actually cannot — has been a known weak spot across the Grok 4.x beta series. According to background reporting, xAI's multi-agent architecture underpinning Grok 4.20 uses a peer-review mechanism among four specialized internal agents, which helps catch and suppress these overconfident incorrect outputs before they reach the user.
📐 Scientific Text Quality (LaTeX)
For researchers, engineers, and educators, the LaTeX rendering improvement is significant. Equations and scientific notation displayed incorrectly — or broken mid-formula — can make an AI model practically useless in technical workflows. This update refines how Grok parses and renders LaTeX markup, making it a more viable co-pilot for academic and engineering use cases.
🔍 Image Search Trigger Precision
Grok's image search functionality has occasionally fired at unintended moments, or failed to activate when a visual query clearly warranted it. Beta 2 tightens the trigger logic so image searches are invoked more predictably and accurately — reducing both false positives (unnecessary image searches) and false negatives (missed visual lookups).
🖼️ Multiple Image Render Reliability
Multi-image responses — particularly when Grok generates or retrieves several images in a single reply — have suffered from occasional rendering failures. This fix improves the stability of those multi-image outputs, which is especially relevant for design, research, and content-generation workflows where a single dropped image breaks the entire response.
🔭 The BASENOR Take
Timeline: Beta rollout live as of March 3, 2026 — API access still listed as "coming soon"
Impact Level: Medium — meaningful reliability improvements, not a capability leap
Confidence: High — confirmed directly by the official @grok account; background details corroborated by multiple independent sources
Grok 4.20 Beta 2 is not a headline-grabbing model launch. It is something arguably more valuable: disciplined refinement. The five improvements listed are all reliability fixes — the unglamorous engineering work that turns a promising beta into a dependable tool.
For Tesla owners paying attention to the Grok trajectory, the hallucination reduction is the most consequential item on this list. xAI's multi-agent architecture — where specialized agents cross-check each other's outputs — was introduced with the broader Grok 4.20 series and represents a structural, not just tuning-level, approach to accuracy. Each beta iteration that tightens that system moves Grok closer to being a credible tool for high-stakes queries: engineering analysis, medical second opinions, and complex multi-document reasoning.
The LaTeX improvements, meanwhile, signal where xAI sees Grok's long-term user base: not casual chatbot interactions, but professional and technical workflows where precision formatting is non-negotiable. Combined with the 2-million-token context window that the 4.20 series carries, Grok is increasingly positioned as a serious competitor in the enterprise and research AI space — a market where reliability patches like Beta 2 matter far more than flashy feature announcements.
API access remains the outstanding bottleneck. Until Grok 4.20 is accessible to developers programmatically, its real-world adoption in third-party tools and integrations will remain limited. Once that gate opens, expect a much broader test of whether these reliability improvements hold at scale.

Sarah focuses on Tesla Energy, SpaceX missions, and the broader Musk AI portfolio. Former data analyst in clean energy. Based in San Francisco.
Sources verified at publish time. Spotted an inaccuracy? Email editorial@basenor.com.