30-Second Brief
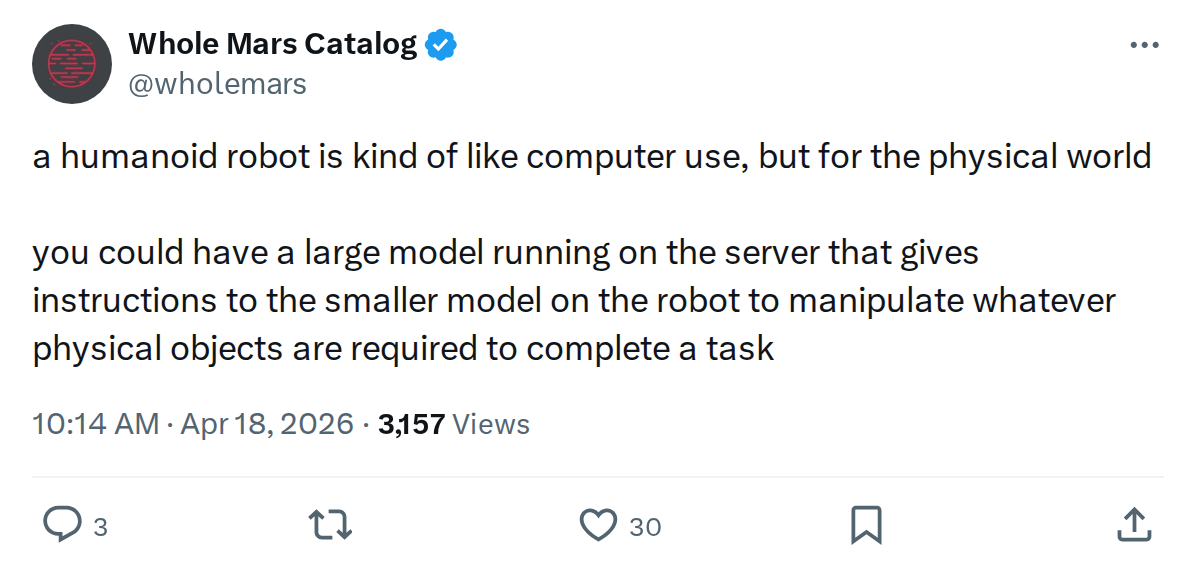
The News: Whole Mars Catalog proposes that humanoid robots could operate via a two-tier AI architecture — a large model on a remote server issuing instructions to a smaller, on-device model that handles physical manipulation.
Why It Matters: This framework maps directly onto how Tesla is building Optimus, and it could define how capable — and how scalable — the next generation of humanoid robots becomes.
Source: @wholemars on X
The Two-Brain Model: How Humanoid Robot AI Could Actually Work
The question of how a humanoid robot "thinks" is one of the most consequential engineering problems in AI right now. A framework surfaced overnight by Whole Mars Catalog cuts through the complexity with a surprisingly elegant analogy — and it lines up closely with what Tesla appears to be building inside Optimus.

The Computer Use Analogy — And Why It's Useful
Whole Mars Catalog frames humanoid robots as "computer use, but for the physical world." That's a precise comparison. Computer use AI — where a model controls a cursor, reads a screen, and executes software tasks — requires two things: high-level reasoning about what to do, and low-level precision about how to do it. Humanoid robots need exactly the same split, just in meatspace instead of a browser window.
The proposed architecture separates these concerns cleanly:
- Large model (server-side): Handles planning, reasoning, and task decomposition. It understands the goal — "make coffee," "assemble this part," "sort these packages" — and breaks it into a sequence of sub-instructions.
- Small model (on-robot): Executes those instructions in real time, managing the fine-grained physical manipulation — grip force, object tracking, spatial awareness, balance correction — that requires low latency and can't wait on a network round-trip.
📊 Key Figures
| Dimension | Server Model | On-Robot Model |
|---|---|---|
| Primary Role | Task planning & instruction | Physical manipulation & execution |
| Model Size | Large (compute-intensive) | Small (latency-optimized) |
| Latency Requirement | Tolerant (seconds) | Critical (milliseconds) |
| Tesla Parallel | Dojo / cloud inference | FSD-derived on-device chip |
Where Tesla Optimus Fits
This isn't purely theoretical for Tesla. According to available information on Optimus Gen 3, the robot's "brain" is directly inherited from Tesla's Full Self-Driving system — an end-to-end, large-scale model that processes visual data from cameras, understands motion and spatial context, and handles planning and reasoning. That FSD-derived architecture already functions as the on-device intelligence layer described in the two-brain framework.
The server-side component — the large model issuing higher-level instructions — maps naturally onto Tesla's Dojo supercomputer and its cloud inference infrastructure. Tesla already uses this split in the FSD pipeline: heavy neural net training and some inference happens in the cloud, while real-time driving decisions execute on the vehicle's onboard AI chip. Extending that pattern to a humanoid robot is an architectural evolution, not a reinvention.
For more context on how Tesla's self-driving AI underpins this approach, see our FSD coverage.
Why the Split Matters for Scalability
The two-brain model isn't just an engineering convenience — it's a scalability unlock. A single large model running entirely on-device would require significant compute hardware in every robot, driving up cost and weight while generating heat in a chassis that needs to move fluidly. By offloading the heavy reasoning to a server, you can deploy a leaner, cheaper on-robot chip without sacrificing task intelligence.
More importantly, the server-side model can be updated independently. Improve the planning model in the cloud, and every robot in the fleet benefits immediately — no OTA update required for the physical hardware. That's the same logic that makes Tesla's over-the-air software updates so powerful for its vehicles, applied to robotics.
🔭 The BASENOR Take
Timeline: Conceptual framework — production implementation in Optimus is ongoing as of 2026
Impact Level: High — architectural decisions made now will determine Optimus's commercial ceiling
Confidence: Medium — the framework is logical and consistent with Tesla's known approach, but specific implementation details remain unconfirmed
The framing here is sharp and worth taking seriously. Whole Mars Catalog has a track record of articulating Tesla's technical direction clearly, and the computer-use analogy is genuinely illuminating. The most important implication for Tesla owners and investors: if Optimus runs on a two-brain architecture, the robot's intelligence ceiling is effectively determined by the server-side model — which means it improves continuously as AI scales, independent of hardware refresh cycles.
That's a fundamentally different value proposition than a robot with fixed on-device intelligence. It also means Tesla's existing AI infrastructure — Dojo, its inference clusters, the FSD neural net lineage — becomes a direct competitive moat in the humanoid robot race. Companies without that server-side AI foundation would need to either build it from scratch or license it, neither of which is fast or cheap.
The open question is latency and connectivity. A robot that depends on a server for high-level instructions is only as reliable as its network connection. For factory floors with robust Wi-Fi, that's manageable. For more dynamic or remote environments, the on-device model needs to be capable enough to handle degraded connectivity gracefully. That's the engineering tension this architecture has to solve — and it's likely where the most interesting Optimus development is happening right now.

Sarah focuses on Tesla Energy, SpaceX missions, and the broader Musk AI portfolio. Former data analyst in clean energy. Based in San Francisco.
Sources verified at publish time. Spotted an inaccuracy? Email editorial@basenor.com.