📌 UPDATE — May 28, 2026
Elon Musk has confirmed the next phase of the AI stack development goes beyond training: an inference stack written in C is now planned, targeting simultaneous high-speed reinforcement learning across large blocks of Nvidia GB300 GPUs — applicable to both xAI and Tesla. Musk also clarified that while the stack is predominantly C, a small amount of C++ is used in practice. This signals the bare-metal, low-level approach extends to the full training-to-inference pipeline, not just the training layer covered in our original report.

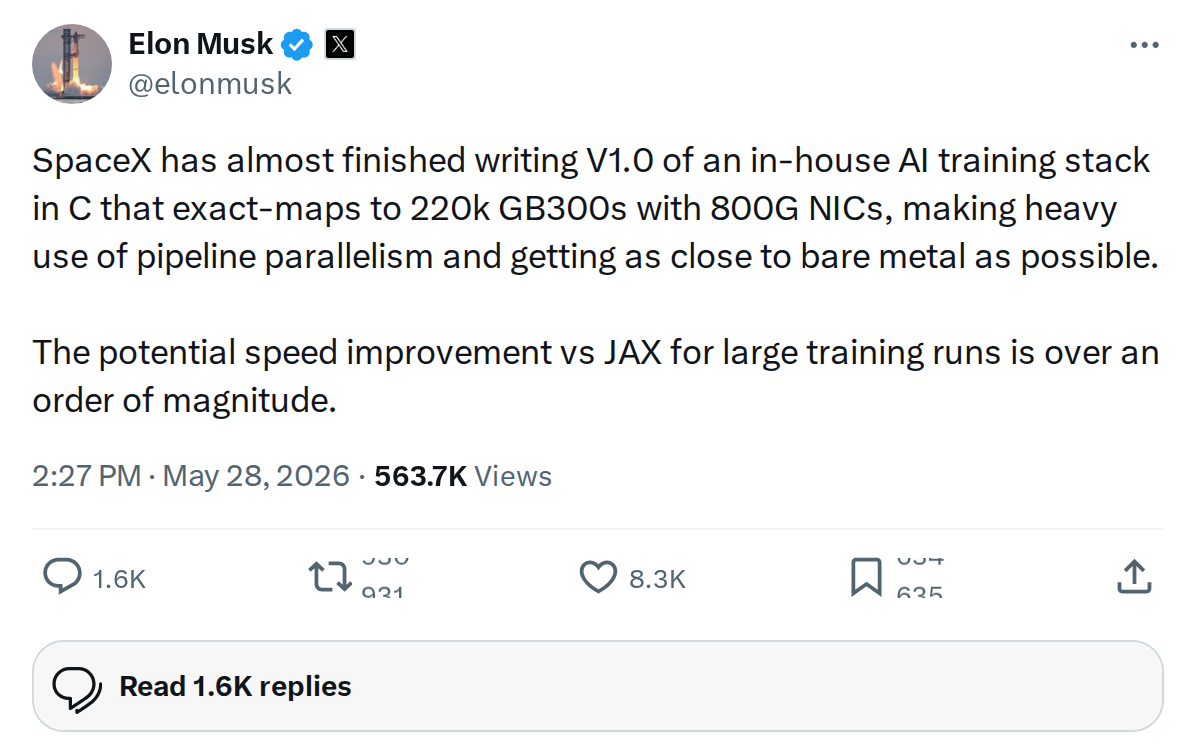
@elonmusk · May 28, 2026 · 97K views
SpaceX is close to finishing a fully custom AI training stack — written in C, optimized for 220,000 NVIDIA GB300 GPUs, and designed to squeeze every bit of performance out of bare metal. Elon Musk revealed the project on X, noting it makes heavy use of pipeline parallelism and 800G network interface cards. The implied speed improvement over existing frameworks like JAX, for large training runs, could be substantial — though Musk left the exact figure as a cliffhanger in his post.

Why Build From Scratch?
Most AI labs train on frameworks like JAX, PyTorch, or custom derivatives that abstract away the hardware. Those abstractions are convenient — but they carry overhead. Every layer of software between your training job and the GPU costs cycles. At the scale SpaceX is operating, that overhead compounds fast.
Writing directly in C and mapping the software exactly to the physical hardware — 220,000 GB300 chips connected via 800G NICs — eliminates those layers. Pipeline parallelism, which splits a model across multiple devices and keeps them all busy simultaneously, becomes far easier to tune when you control the entire stack. The result, in theory, is a training cluster that runs closer to its theoretical maximum throughput than any general-purpose framework can achieve.
This isn't a novel idea in principle — Google built TPUs and XLA for exactly this reason — but doing it at this scale in C, targeting commodity NVIDIA hardware rather than custom silicon, is a different kind of bet.
The Infrastructure Behind It
To understand the ambition here, the numbers matter. According to verified reporting, SpaceX operates two major AI training clusters. Colossus I houses over 220,000 NVIDIA GPUs including H100s, H200s, and GB200s — the cluster that Anthropic has contracted to use, paying $1.25 billion per month through May 2029. Colossus II, which came online at gigawatt-scale power in January 2026, holds approximately 550,000 to 555,000 NVIDIA Blackwell-series GPUs, primarily GB200 and GB300 chips, with plans to scale toward one million GPUs.
Colossus II is currently running seven parallel AI model training jobs, including variants scaling up to 10 trillion parameters. That's the environment this new training stack is being built for — not a research cluster, but an active, production-scale AI factory.

What This Means for the AI Race
SpaceX's S-1 registration statement, filed ahead of its planned IPO, explicitly reframes the company as a vertically integrated AI infrastructure platform — encompassing compute, satellite networking, orbital data centers, and energy systems. The filing argues that future AI competition will be decided by control of underlying physical systems: chips, energy, networking, manufacturing, and deployment capacity.
A proprietary training stack is a direct extension of that thesis. If SpaceX can train models meaningfully faster than competitors using the same NVIDIA hardware, it gains an asymmetric advantage — more model iterations per dollar, faster research cycles, and a moat that doesn't depend on getting scarce next-generation chips first.
The broader Musk ecosystem stands to benefit too. Tesla's Dojo supercomputer has pursued a similar philosophy — custom silicon, custom interconnects, custom software — for autonomous driving training. A proven bare-metal training stack developed at SpaceX could inform or accelerate that work, though the two remain separate organizations with separate compute infrastructure.
Version 1.0 isn't finished yet, and benchmark numbers haven't been published. But the direction is clear: SpaceX is betting that owning the full stack — from the C code to the GPU to the data center power supply — is the only way to compete at the frontier of AI. Whether the speed gains match the ambition is the question that V1.0 will have to answer.

Sarah focuses on Tesla Energy, SpaceX missions, and the broader Musk AI portfolio. Former data analyst in clean energy. Based in San Francisco.
Sources verified at publish time. Spotted an inaccuracy? Email editorial@basenor.com.