The News: Tesla's Cortex 2 AI training cluster is now online at Giga Texas and has begun processing training workloads.
Why It Matters: Cortex 2 is the compute backbone behind Tesla's FSD and Optimus development — its activation marks a significant step-up in Tesla's in-house AI training capacity.
Source: @SawyerMerritt on X
Tesla's Cortex 2 AI Training Cluster Is Now Live — What It Means for FSD and Optimus
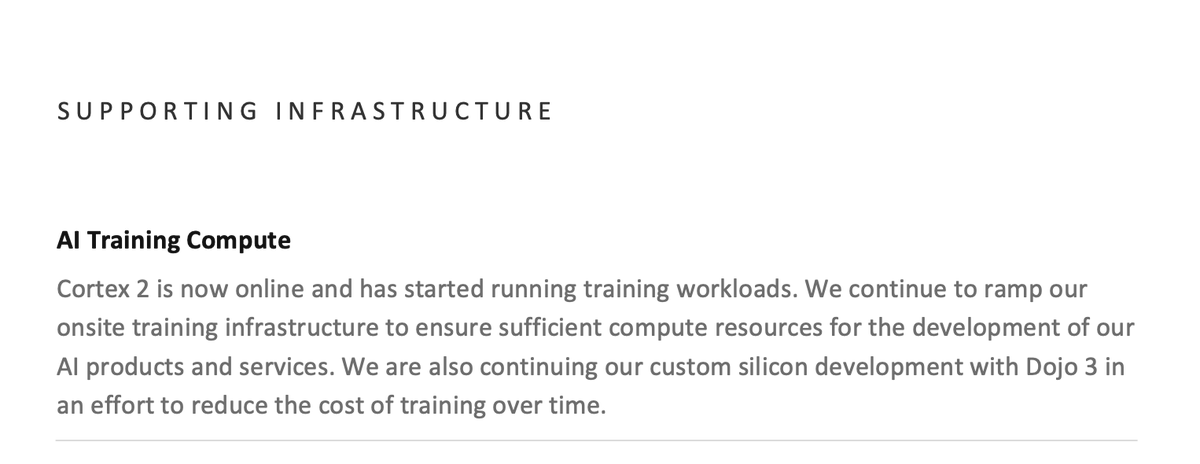
Tesla just confirmed that Cortex 2, its next-generation AI supercomputing cluster located at Giga Texas, is now online and actively running training workloads. The announcement, shared by Tesla and reported by @SawyerMerritt, signals that the company's most powerful in-house AI infrastructure to date has crossed from construction into active operation — right on schedule.

For Tesla owners, this isn't abstract data center news. Every improvement to Full Self-Driving — every smoother lane change, every better phantom braking fix, every new FSD capability — traces back to raw compute power. Cortex 2 is where the next generation of those improvements gets trained.
📊 Key Figures
| Metric | Value | Context |
|---|---|---|
| Phase 1 Capacity | 250 MW | Now active (April 2026) |
| Full Capacity Target | 500 MW | Expected mid-2026 |
| GPU Count (at full build) | ~100,000 | Nvidia H100/H200 GPUs |
| Location | Giga Texas | Austin, TX |
| Primary Workloads | FSD + Optimus | AI training for both programs |
From Cortex 1 to Cortex 2: A Massive Leap in Scale
The original Cortex cluster — which Tesla brought online at Giga Texas in mid-2024 — was itself a landmark achievement, deploying tens of thousands of Nvidia H100 GPUs to accelerate FSD training. But demand for compute has grown faster than even Tesla anticipated. FSD's video-based neural network training is extraordinarily data-intensive, and Optimus — Tesla's humanoid robot program — adds an entirely new category of training requirements on top of that.
Cortex 2 is designed to address that compute gap at a scale that few companies outside of the hyperscalers have attempted. At full build-out, the cluster is expected to draw 500 megawatts of power — enough to supply a mid-sized city — and house approximately 100,000 Nvidia H100 and H200 GPUs. The first 250 MW phase, which has now activated, puts Cortex 2 in a class of its own among automaker-owned AI infrastructure.
What Cortex 2 Is Actually Training
Full Self-Driving (FSD): Tesla's FSD system learns by processing massive datasets of real-world driving video collected from its fleet. The more compute available, the faster Tesla can iterate on its neural networks — compressing what might take months of training into weeks. Cortex 2 coming online means Tesla can run larger models, on more data, faster than before. For owners waiting on FSD improvements, this is the infrastructure that makes those improvements possible. You can follow our FSD coverage for the latest updates as new capabilities roll out.
Optimus: Tesla's humanoid robot requires a fundamentally different type of AI training than FSD — learning physical manipulation, spatial reasoning, and task execution in varied environments. Cortex 2's scale is partly a direct response to Optimus's training demands, which Tesla has described as requiring compute resources comparable to its vehicle AI programs.
The Custom Silicon Angle: Dojo 3 in Development
Tesla's announcement also confirmed that custom silicon development is continuing — a reference to the company's Dojo program. While Cortex 2 currently runs on Nvidia GPUs, Tesla has been building its own AI training chips (the D1 chip and Dojo system) with the explicit goal of reducing training costs over time.
According to verified reports, Dojo 3 is in active development. The strategic logic is straightforward: at the scale Tesla is operating — hundreds of megawatts of compute, potentially 100,000+ GPUs — even modest cost-per-compute improvements translate into hundreds of millions of dollars in savings annually. Custom silicon also gives Tesla architectural control that off-the-shelf GPUs cannot provide.
The combination of Cortex 2 (Nvidia-powered, available now) and Dojo 3 (custom silicon, in development) represents Tesla's two-track compute strategy: buy what you need today, build what you need for tomorrow.
🔭 The BASENOR Take
Timeline: Phase 1 (250 MW) active April 2026 → Full 500 MW capacity targeted mid-2026
Impact Level: 🔴 High — directly accelerates FSD iteration speed and Optimus development timeline
Confidence: ✅ Confirmed — Tesla's own statement, reported by @SawyerMerritt
The activation of Cortex 2 is one of those milestones that doesn't generate a flashy product reveal but quietly determines how fast everything else moves. Tesla's competitive moat in autonomous driving isn't just its fleet size or its camera-only approach — it's the speed at which it can train, test, and deploy improvements. Cortex 2 is the engine that drives that speed.
Consider the compounding effect: more compute means faster training cycles, which means more FSD software versions per year, which means more improvement per mile driven by the fleet. Tesla has historically released FSD updates on a cadence tied partly to training throughput. With Cortex 2 online and ramping toward 500 MW, that cadence could accelerate meaningfully in the second half of 2026.
The Optimus dimension is equally significant. Tesla has set ambitious production targets for its humanoid robot, and hitting those targets requires not just manufacturing scale but AI capability that can only come from massive training infrastructure. Cortex 2 is as much an Optimus investment as it is an FSD one.
Finally, the continued investment in Dojo 3 signals that Tesla views compute as a long-term strategic asset — not just a cost center. If Dojo 3 delivers meaningful cost reductions at scale, Tesla's AI training economics could diverge sharply from competitors who remain dependent on third-party GPU suppliers. That's a structural advantage that compounds over years, not quarters.

Sarah focuses on Tesla Energy, SpaceX missions, and the broader Musk AI portfolio. Former data analyst in clean energy. Based in San Francisco.
Sources verified at publish time. Spotted an inaccuracy? Email editorial@basenor.com.