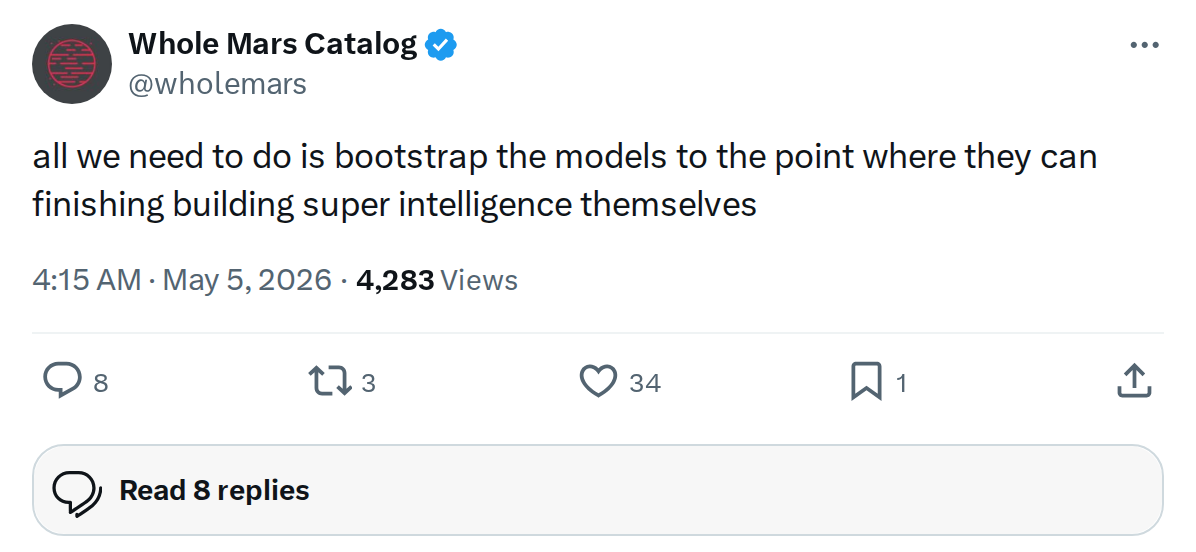
Something significant is happening inside xAI's labs. According to Whole Mars Catalog — a close observer of Musk's ventures — the recursive self-improvement loop that AI researchers have long theorized about is no longer hypothetical. It's underway. The models being trained at xAI are now actively helping write the code used to train them, and generating a substantial share of their own training data in the process.

The framing is deliberate: this isn't AI assisting engineers on the side. The code governing training pipelines, inference systems, and both client- and server-side operations is being written faster and with higher quality because the model being trained is contributing to its own development. It's a feedback loop — and it's accelerating.
The stated goal, per the same source, is to bootstrap the models to a threshold where they can finish the job themselves.

That framing aligns with xAI's broader trajectory. Elon Musk has projected AGI could arrive as early as 2026, a timeline he's tied to the rapid iteration of the Grok model series and the sheer scale of xAI's Colossus supercomputer — which had already deployed approximately 200,000 GPUs for Grok 3 training as of early 2025, with plans to scale to one million. The company's $20 billion funding round, which pushed its valuation to $230 billion, was explicitly earmarked for expanding that compute infrastructure.
Recursive self-improvement has always been the theoretical inflection point in AI development — the moment a system becomes capable enough to meaningfully improve its own architecture and training process, compounding gains without proportional human input. Whether xAI has crossed that threshold or is simply approaching it remains an open question. But the description of models generating a large part of their own training set, while simultaneously accelerating the code written around them, suggests the gap between theory and practice is closing faster than most outside observers expected.

Sarah focuses on Tesla Energy, SpaceX missions, and the broader Musk AI portfolio. Former data analyst in clean energy. Based in San Francisco.
Sources verified at publish time. Spotted an inaccuracy? Email editorial@basenor.com.